
Notices by Phantasm (phnt@fluffytail.org), page 7
-
Phantasm (phnt@fluffytail.org)'s status on Sunday, 18-Aug-2024 09:22:32 JST  Phantasm
Phantasm
@mint -
Phantasm (phnt@fluffytail.org)'s status on Friday, 16-Aug-2024 23:24:13 JST
Phantasm
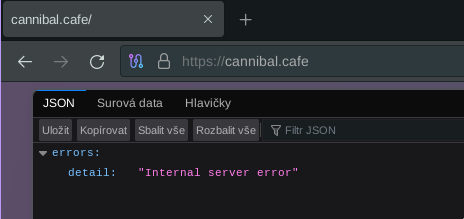
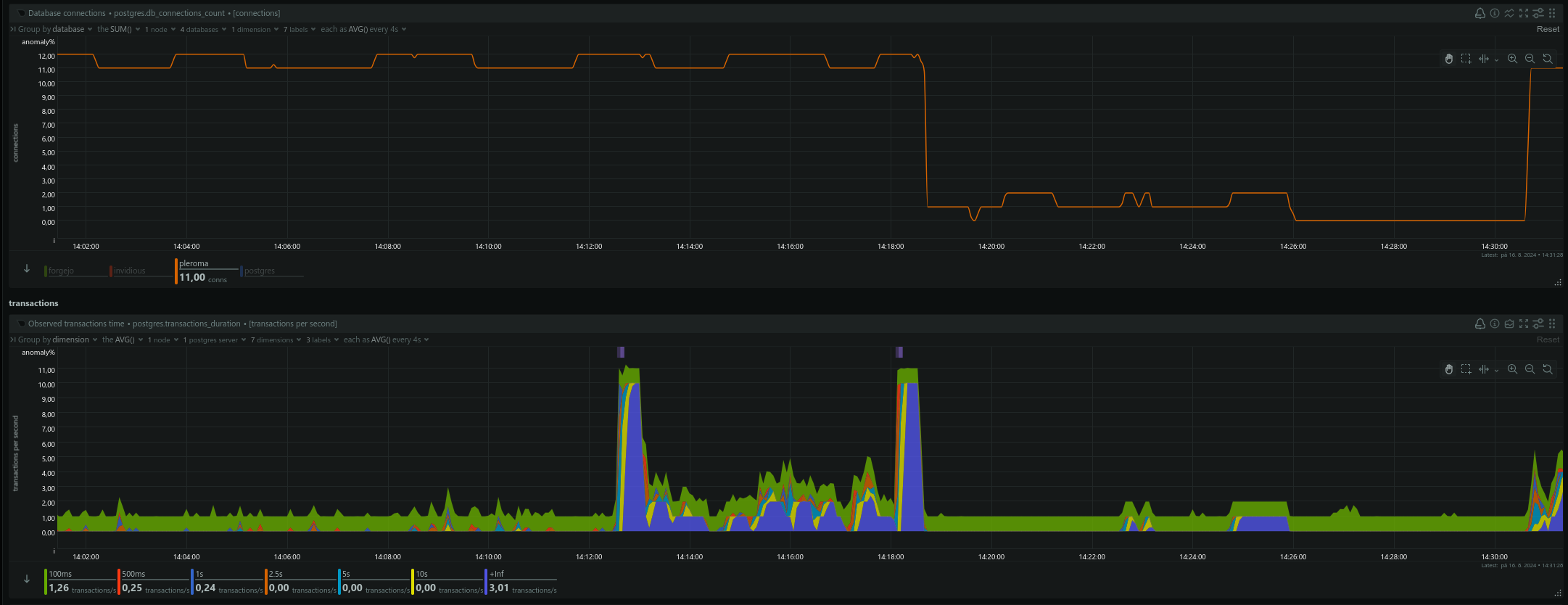
@feld @mint @phnt Pleroma crashed again ~1 minute after I made a post. federator_incoming queue had 0 available jobs, and few retryable. federator_outgoing had 7 failed jobs and zero available/executing.
Same thing just like last time. Out of nowhere a jump in disk backlog for a minute, disk busytime and Pleroma DB locks. Had almost zero DB timeouts before that.
Before the crash a lot of (DBConnection.ConnectionError) connection not available and request was dropped from queue after <some number>ms. This means requests are coming in and your connection pool cannot serve them fast enough. showed up in logs. Pleroma used at maximum 12 DB connections. Number of connections or pool size are from the default config, only :pleroma :connections_pool, connect_timeout was increased to 10s from default 5s. :pleroma, Pleroma.Repo, timeout was also increased to 30s.
The Netdata screenshots are from the same time. Ignore the time difference. Server is UTC-4 (US ET) and Netdata is UTC+2 (CEST).
pleroma-crash_20240816.txt
postgres-crash_20240816.txt -
Phantasm (phnt@fluffytail.org)'s status on Thursday, 15-Aug-2024 03:47:14 JST
Phantasm
@feld @phnt @mint Updated instance to the newest commit on feld/debugging and downgraded Oban. There's no point in me trying to find it on my own as I have no other clues.
Will report back if it stalls again. -
Phantasm (phnt@fluffytail.org)'s status on Thursday, 15-Aug-2024 03:14:28 JST
Phantasm
the I/O should really be minimal which is what's baffling
I've looked through the 2.17.0 release notes and sorentwo mentioned disabling the insert trigger functionality completely in config if "sub-second job execution isn't important." That should disable the insert trigger functionality that I suspected of the increased I/O and revert to polling only. After changing that with config :pleroma, Oban, insert_trigger: false the I/O did not change in any way. Still the same behavior. At this point I'm kinda lost at what the issue might be.
The documentation and release notes also mention different reasons for disabling the trigger:
https://github.com/sorentwo/oban/releases/tag/v2.17.0
https://hexdocs.pm/oban/v2-17.html#disable-insert-notifications-optionalI've also skimmed through Ecto and Postgrex GitHub issues and didn't find anything meaningful that mentioned increased I/O or Oban.
-
Phantasm (phnt@fluffytail.org)'s status on Thursday, 15-Aug-2024 02:41:35 JST
Phantasm
@mint @phnt @feld
> The theory might be true; worth noting that postgrex crashes used to cascade into crashing the whole pleroma
Similar thing happened to me, stalled federation and an hour later all connections on localhost were refused (Pleroma did not listen on it's port). When I used IEx to get access to it, IEx had no idea what Oban and Ecto were. -
Phantasm (phnt@fluffytail.org)'s status on Thursday, 15-Aug-2024 01:54:39 JST
Phantasm
Alex Gleason does something very brave to deal with existing Rebased users. He simply doesn't care.
RT: https://gleasonator.com/objects/5072efd0-5aa9-406c-bf11-e8ef7d5c0dce -
Phantasm (phnt@fluffytail.org)'s status on Tuesday, 13-Aug-2024 21:15:33 JST
Phantasm
Crypto markets -
Phantasm (phnt@fluffytail.org)'s status on Monday, 12-Aug-2024 16:58:54 JST
Phantasm
Now that Gleason moved to Nostr, Fedi is finally a bit better without the constant Nostr shilling. It's like the only one that actually cared was Gleason all along :senkohmm: -
Phantasm (phnt@fluffytail.org)'s status on Monday, 12-Aug-2024 04:32:47 JST
Phantasm
@graf @j @p @anonaccount Makes sense, it's probably a concern only for VPS and server providers that effectively allow running any code on their machines. If company systems get infected by this, it was game over long before that. -
Phantasm (phnt@fluffytail.org)'s status on Sunday, 11-Aug-2024 17:30:25 JST
Phantasm
@p @j @anonaccount @graf It's already fixed for some EPYC and desktop CPUs. The patch requires a bios flash or a microcode update to prevent the infection (not fix it).
https://www.amd.com/en/resources/product-security/bulletin/amd-sb-7014.html
One article I read also implies that the malware has to be loaded during boot for the exploit to work which should be preventable with secure boot. -
Phantasm (phnt@fluffytail.org)'s status on Saturday, 10-Aug-2024 20:57:14 JST
Phantasm
@mint @j @p @graf @sun I guess I'm important enough for them to merit a follow. From the surface it seems like another Awakari/Maven thing that scrapes posts and puts some tags on them for searchability and personalized feeds. I'm not too fond of that even though almost all of my posts are public. -
Phantasm (phnt@fluffytail.org)'s status on Saturday, 10-Aug-2024 18:22:06 JST
Phantasm
@p @graf @j @sun @mint
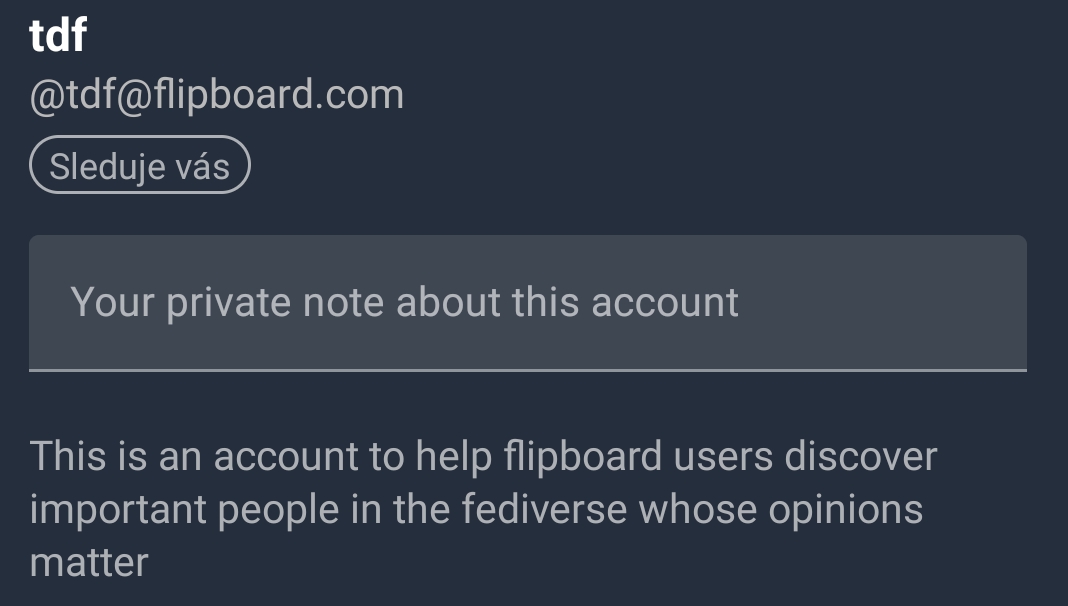
A possible new corporate followbot/scraper has surfaced on the now somewhat old flipboard.com site that reposts news articles.
Handle: tdf@flipboard.com
https://flipboard.com/@tdf
https://about.flipboard.com/ -
Phantasm (phnt@fluffytail.org)'s status on Tuesday, 06-Aug-2024 13:53:47 JST
Phantasm
@feld This instance currently still runs 2.6.3 and therefore isn't affected in any way, but the test instance runs:
Erlang: 25.2.3+dfsg-1
Elixir: 1.14.0.dfsg-2
PostgreSQL: 15
Both are the default Debian 12 packages. I can switch to a more upstream setup with asdf if you want. -
Phantasm (phnt@fluffytail.org)'s status on Tuesday, 06-Aug-2024 13:50:38 JST
Phantasm
@feld, is there a possibility that Oban behavior has changed between versions 2.13.4 and 2.17.9 that could break Pleroma's federation (version update commit: dbf29cba)? This commit is in the 03024318..9953b0da commit range from mint and also before the commit in the issue on Gitlab.
I have a test instance that now runs on that commit to see if it will break. If it doesn't break this week, I'll slowly bisect the commit range.
-
Phantasm (phnt@fluffytail.org)'s status on Tuesday, 06-Aug-2024 01:41:01 JST
Phantasm
Wondering if the market crash will make the AI bubble pop. -
Phantasm (phnt@fluffytail.org)'s status on Monday, 05-Aug-2024 05:55:08 JST
Phantasm
@mint Get well soon, maybe I'll find something. I don't expect meaningful results from it, but it peaked my curiosity and I have too much free time on my hands. -
Phantasm (phnt@fluffytail.org)'s status on Monday, 05-Aug-2024 05:43:47 JST
Phantasm
cc @mint -
Phantasm (phnt@fluffytail.org)'s status on Monday, 05-Aug-2024 05:43:47 JST
Phantasm
@mint Are you still experiencing the stuck federation on your instance and other instances you manage?
Since the issue apparently went into 2.7.0 stable, I'm willing to bisect the 03024318..9953b0da commit range on a throwaway VPS and domain, if that is the commit range when it happened and 03024318 is a known good commit, or at least near a known good commit.
https://ryona.agency/objects/7bcdc6a8-3895-4fa2-80c4-241e171ab398 -
Phantasm (phnt@fluffytail.org)'s status on Sunday, 04-Aug-2024 05:51:37 JST
Phantasm
@sapphire @Goalkeeper @Myshkin @matty @niggy Honestly finding vulnerabilities is probably too much work. These callcenters are ran by incompetent people, systems running cracked versions of Windows (usually already EOL), cracked client software, outdated apps. To my knowledge most of these remote desktop solutions leak your IP. If they are a business, they likely don't have a NAT at the ISP level.
Just get their IP somehow and hammer the very likely vulnerable router, or target old client software with vulns when they are connected to you. -
Phantasm (phnt@fluffytail.org)'s status on Friday, 02-Aug-2024 05:46:11 JST
Phantasm
TIL that you apparently can't define ports in a custom SELinux policy. You have to create the type and then manually assign the port after the policy is installed. The network_port macro will throw a syntax error, because it's a fucking m4 macro that is only available when building the whole default policy.
Evil.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}